1708362584
2024-02-17 12:40:01
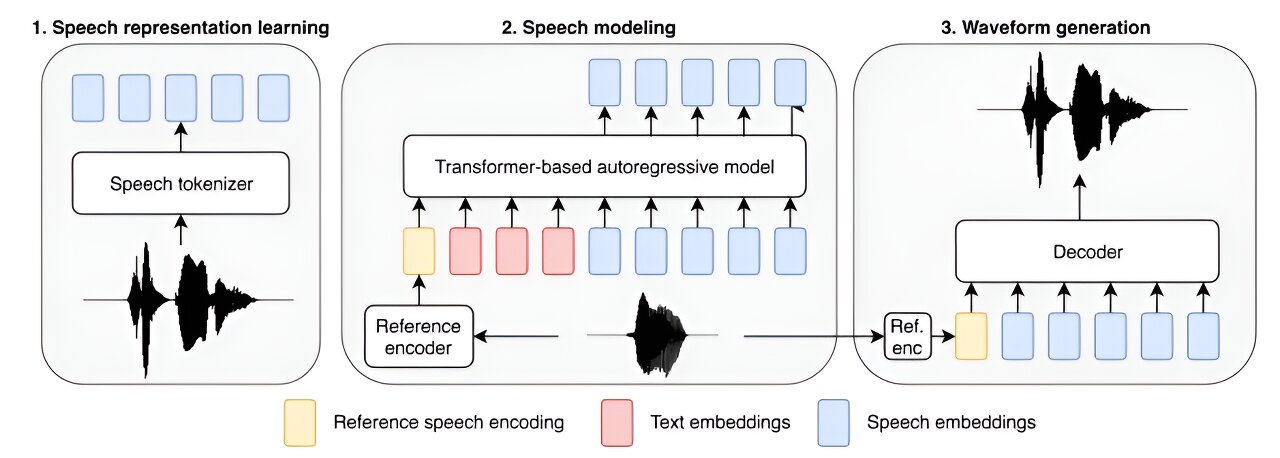
BASE TTSの概要。 音声トークナイザー (1) は、テキストと参照音声を条件とした自己回帰モデル (2) によってモデル化された離散表現を学習します。 音声コード デコーダ (3) は、予測された音声表現を波形に変換します。 クレジット: arXiv (2024年)。 DOI: 10.48550/arxiv.2402.08093
Amazon AGI の人工知能研究者チームは、史上最大のテキスト読み上げモデルと称されるものの開発を発表しました。 最大とは、パラメータが最も多く、最大のトレーニング データセットを使用することを意味します。 彼らは出版しました 紙 で arXiv モデルがどのように開発およびトレーニングされたかを説明するプレプリント サーバー。
ChatGPT のような LLM は、質問にインテリジェントに答え、高レベルのドキュメントを作成する人間のような能力で注目を集めています。 しかし、AI は依然として他の主流アプリケーションにも進出し続けています。 この新しい取り組みにおいて、研究者らは、パラメータの数を増やし、トレーニング ベースを追加することによって、テキスト読み上げアプリケーションの能力を向上させようと試みました。
新しい モデルは、創発機能を備えた Big Adaptive Streamable TTS (略して BASE TTS) と呼ばれ、9 億 8,000 万のパラメータを持ち、100,000 時間の録音された音声 (公開サイトにある) を使用してトレーニングされました。そのほとんどは英語でした。 チームはまた、他の言語で話されている単語やフレーズの例も与え、モデルがよく知られたフレーズ、たとえば「au contrare」や「adios, amigo」などに遭遇したときに正しく発音できるようにしました。
Amazon のチームはまた、AI 分野で新興品質として知られるようになった機能がどこで開発されているかを知ることを目的として、小規模なデータセットでモデルをテストしました。LLM またはテキスト読み上げアプリケーションのいずれであっても、AI アプリケーションはその中で開発されています。 、突然、より高いレベルの知性へと突き抜けたようです。 彼らは、アプリケーションの場合、パラメータ数が 1 億 5,000 万という中規模のデータセットで、より高いレベルへの飛躍が起こることを発見しました。
彼らはまた、この飛躍には、複合名詞の使用、感情の表現、外来語の使用、パラ言語学と句読点の適用、適切な単語に重点を置いて質問する能力など、多くの言語属性が関係していると指摘しました。文。
チームは、BASE TTS は非倫理的に使用されることを恐れて一般にはリリースされず、代わりに学習アプリケーションとして使用する予定だと述べています。 彼らは、これまでに学んだことを応用して、テキスト読み上げアプリケーション全体の人間らしい音質を向上させることを期待しています。
詳しくは:
Mateusz Łajszczak et al、BASE TTS: 10 万時間のデータに基づく 10 億パラメータの音声合成モデルの構築からの教訓、 arXiv (2024年)。 DOI: 10.48550/arxiv.2402.08093
© 2024 サイエンス X ネットワーク
引用: Amazon、これまでに作成された最大のテキスト読み上げモデルを公開 (2024 年 2 月 17 日) https://techxplore.com/news/2024-02-amazon-unveils-largest-text-speech.html より 2024 年 2 月 19 日に取得
この文書は著作権の対象です。 個人的な研究や研究を目的とした公正な取引を除き、書面による許可なしにいかなる部分も複製することはできません。 コンテンツは情報提供のみを目的として提供されています。
#Amazon史上最大のテキスト読み上げモデルを発表